DDPG
Deep Deterministic Policy Gradient combines a deterministic actor, Q-critic, replay buffer, and soft target networks.
Abstract. DDPG is the first concrete algorithm in the off-policy policy-based branch. It takes the framework from the previous chapter and makes it practical for continuous control: learn a critic, learn a deterministic actor , train from a replay buffer, and use target networks for stable bootstrapping. The actor is a differentiable replacement for the greedy step from DQN.
The previous chapter changed the question. On-policy policy-based methods collected fresh trajectories and updated the policy from those trajectories. The new goal is different: keep a policy-based method, but make it off-policy, so old transitions in a replay buffer can still be useful.
DDPG is the first simple answer. It keeps the DQN idea of learning a -function from replay, but replaces the discrete greedy action with a learned continuous actor. The critic says which actions look good. The actor learns to output actions that the critic scores highly.
From DQN to a Policy-Based Actor
Start with the value-based case. DQN performs implicit greedy policy improvement:
There is no separate actor network here. The policy is hidden inside the rule "choose the action with the largest value." This is why DQN works naturally in discrete action spaces: the network outputs one number per action, and the agent picks the largest one.
Continuous actions break this rule. If , there are infinitely many possible actions. In principle, we could still write
but now it means solving a continuous optimization problem every time the agent acts. We would also need to solve the same inner optimization when building training targets. That is too expensive and unstable for the simple DQN loop.
There is another problem. The itself does not give a useful differentiable actor loss. If we want a neural policy, we need a way to update its parameters directly.
DDPG's idea is to learn the argmax with an actor:
The actor is deterministic: for a given state, it returns one action. Then policy improvement becomes the smoother objective
This is the deterministic special case of the reparameterization trick route from the previous chapter. There we wrote a differentiable action as and optimized . In DDPG there is no policy noise inside the actor, so the action path becomes simply .
This is still policy improvement, but now the improvement operator is approximate. The actor is not guaranteed to find the exact best action for every state. It is trained to move its output toward actions that the current critic scores higher.
The gradient uses the pathwise, or reparameterization-style, route. For one minibatch,
By the chain rule,
The critic tells us how the value changes if the action changes. The actor tells us how its action changes if its parameters change. Multiplying them gives a direction for changing the actor.
There is a useful mental model here. DDPG has a training shape that looks like a GAN: one network supplies a learned objective for another network. The critic is trained to predict returns. The actor is trained to maximize the critic. This coupling is powerful, but it is also fragile and can be unstable.
Exploration in Continuous Spaces
A deterministic actor always chooses the same action in the same state. That is exploitation, not exploration. In a continuous action space, we cannot use -greedy in the same simple way as DQN: "choose a random action" means sampling a point from a whole action box, which can be too broad and often ignores what the current actor has learned. Imagine that we train a car to follow a road. With an -greedy-style rule, the agent would usually follow the actor, but at a random moment it might replace the actor's steering command with a completely random one. The wheel could suddenly turn hard left or hard right, and then return to the previous command on the next step. This is not a useful driving exploration pattern. It creates a sharp, unnatural action, and after one step the car is almost back to the same behavior. We need exploration that stays near the current action and changes it smoothly enough to produce a meaningful new trajectory.
DDPG explores by adding noise to the actor's action during data collection:
The noisy action is executed in the environment and stored in the replay buffer. The usual choice for noise is Gaussian. The learned actor itself stays deterministic: so we don't change the policy, just add some noise to the outputs. This explores locally around the actor's current action. If the actor would drive straight, Gaussian noise tries nearby steering and gently changes values rather than jumping uniformly across the entire action space.
The original DDPG paper used Ornstein-Uhlenbeck noise, a temporally correlated process:
The new noise depends on the previous noise, so the perturbation changes smoothly over time instead of being redrawn independently at every step. The motivation was physical control: robots, cars, and simulated bodies have inertia, so smoothly changing noise can look more natural. Later TD3 experiments found that ordinary Gaussian exploration noise was enough in their benchmarks, so modern implementations often use Gaussian noise for simplicity.
If the actor were stochastic, exploration could live inside the policy itself. A Gaussian policy could sample actions directly, and a reparameterized actor could still backpropagate through the sampled action:
DDPG does not take this route. It keeps the actor deterministic and handles exploration as a behavior-policy detail. SAC will later fold stochasticity and entropy into the actor itself.
Deep Deterministic Policy Gradient
Now we can write the full algorithm. DDPG has four networks:
- online actor ;
- online critic ;
- target actor ;
- target critic .
The target-network idea comes from DQN. In bootstrapped learning, the target contains a value estimate from the same kind of model we are training. If that target is built from the online network, it moves after every gradient step, and the critic keeps chasing a changing label. Target networks make this label slower: they are delayed copies used only for bootstrap targets.
A replay buffer stores transitions collected by the noisy behavior policy. For a sampled transition (from the ) we have
the critic target is
The action is the action that was actually executed, possibly with exploration noise. The next action in the target is different: it comes from the target actor. This is the off-policy part of the update.
The critic minimizes
This is the DQN-style evaluation step. The critic learns to predict the one-step Bellman target from replay data.
The actor maximizes the critic value of its own current actions:
The actor update does not use the replay-buffer action . It uses only the replay-buffer state , asks the current actor what it would do there, and improves that action through the critic.
Finally, both target networks are updated by Polyak averaging:
The coefficient is small, often around . This makes the target networks move slowly, so the critic does not chase a target that changes too sharply.
Putting the pieces together:
initialize actor mu_theta and critic Q_w
initialize target copies mu_theta_bar <- mu_theta, Q_w_bar <- Q_w
initialize empty replay buffer D
while training:
choose action a_t = mu_theta(s_t) + exploration_noise
execute action and store (s_t, a_t, r_t, s_{t+1}, done) in D
sample a minibatch (s, a, r, s', done) from D
y = r + gamma (1 - done) Q_w_bar(s', mu_theta_bar(s'))
update Q_w to minimize (Q_w(s, a) - y)^2
update mu_theta to maximize Q_w(s, mu_theta(s))
Polyak-update mu_theta_bar and Q_w_barProperties and Disadvantages
DDPG can be summarized as
This gives DDPG its main strengths. Replay improves sample reuse and breaks the correlation between consecutive transitions. Target networks stabilize bootstrapping. The same general family of DQN improvements can often be adapted to this setting: prioritized replay, distributional critics, and other replay-buffer tricks all make sense for a critic.
But the same design also creates two main problems.
First, the actor can exploit critic errors. The critic is a learned approximation, but the actor treats it as an objective. If has a wrong narrow peak, the actor can move directly toward that peak. This is why the "DQN + GAN" analogy is useful: the actor learns against a moving learned signal, and errors in that signal can be exploited.
The most important version of this is overestimation bias. In DQN, the over noisy action values can select overestimated actions. DDPG has no explicit discrete , but the deterministic actor is still trained to maximize an approximate critic. If the critic overestimates some action region, the actor may chase it, collect more data there, and reinforce the error.
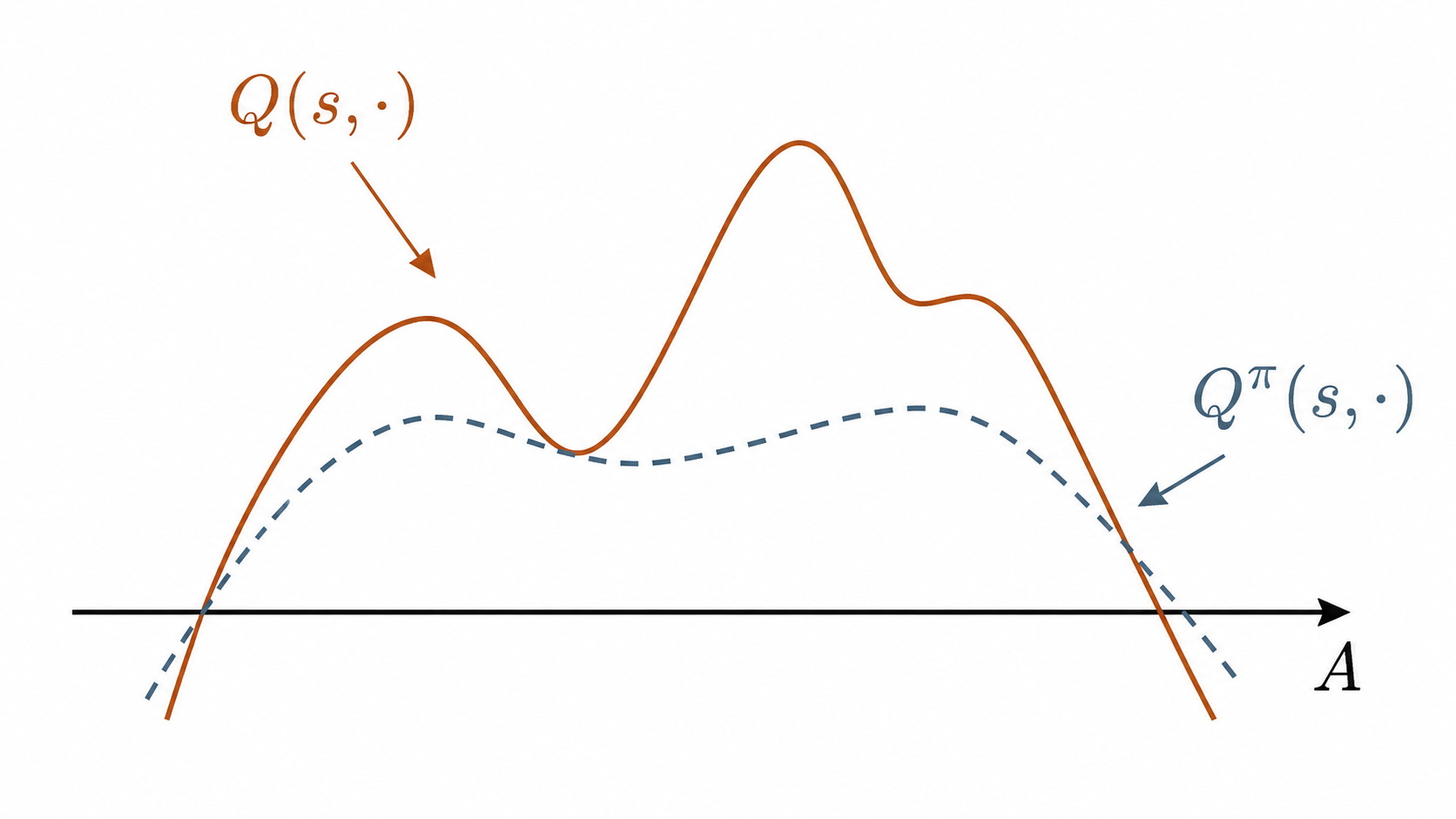
The solid curve is the learned critic's estimate over actions in one state. The dashed curve is the smoother value we would like it to match. A deterministic actor follows the learned curve, so a narrow overestimated peak can become attractive even when it is only a critic error.
Second, DDPG has an exploration problem. A deterministic policy has no entropy and no sampling distribution. Gaussian or Ornstein-Uhlenbeck noise can work, but the noise scale is a hand-tuned behavior-policy choice. Too little noise gives poor exploration. Too much noise makes the replay buffer full of actions far away from the actor's current policy.
There is also a practical sensitivity issue. The original paper used batch normalization because continuous-control observations can mix positions, velocities, angles, and contact signals with very different scales. Even with replay and target networks, the actor-critic feedback loop can be brittle across tasks and random seeds.
Full code
The complete runnable example, including a replay buffer, deterministic actor, Q-critic, action noise, and Polyak target updates:
ddpg.py
You may also find these implementations useful:
What Comes Next
The next chapter keeps the DDPG template and fixes its main weaknesses. TD3 reduces critic overestimation with twin critics, delays actor updates so the critic has more time to learn, and smooths target actions so the actor cannot exploit sharp value spikes. SAC then takes the stochastic route: put exploration into the policy itself and optimize a maximum-entropy objective.